-
Notifications
You must be signed in to change notification settings - Fork 3.4k
Expand file tree
/
Copy pathutils.py
More file actions
271 lines (215 loc) · 8.44 KB
/
utils.py
File metadata and controls
271 lines (215 loc) · 8.44 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
import copy
import os
import random
import shutil
from pathlib import Path
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, TypeVar, Union
import cv2
import numpy as np
import numpy.typing as npt
from supervision.detection.core import Detections
from supervision.detection.utils import (
approximate_polygon,
filter_polygons_by_area,
mask_to_polygons,
)
if TYPE_CHECKING:
from supervision.dataset.core import DetectionDataset
T = TypeVar("T")
def approximate_mask_with_polygons(
mask: np.ndarray,
min_image_area_percentage: float = 0.0,
max_image_area_percentage: float = 1.0,
approximation_percentage: float = 0.75,
) -> List[np.ndarray]:
height, width = mask.shape
image_area = height * width
minimum_detection_area = min_image_area_percentage * image_area
maximum_detection_area = max_image_area_percentage * image_area
polygons = mask_to_polygons(mask=mask)
if len(polygons) == 1:
polygons = filter_polygons_by_area(
polygons=polygons, min_area=None, max_area=maximum_detection_area
)
else:
polygons = filter_polygons_by_area(
polygons=polygons,
min_area=minimum_detection_area,
max_area=maximum_detection_area,
)
return [
approximate_polygon(polygon=polygon, percentage=approximation_percentage)
for polygon in polygons
]
def get_class_distribution(dataset: "DetectionDataset") -> Dict[str, int]:
"""
Returns a dictionary with class names as keys and sample counts as values.
"""
from collections import Counter
all_classes = []
for det in dataset.annotations:
all_classes.extend(det["class_names"])
return dict(Counter(all_classes))
def merge_class_lists(class_lists: List[List[str]]) -> List[str]:
unique_classes = set()
for class_list in class_lists:
for class_name in class_list:
unique_classes.add(class_name)
return sorted(list(unique_classes))
def build_class_index_mapping(
source_classes: List[str], target_classes: List[str]
) -> Dict[int, int]:
"""Returns the index map of source classes -> target classes."""
index_mapping = {}
for i, class_name in enumerate(source_classes):
if class_name not in target_classes:
raise ValueError(
f"Class {class_name} not found in target classes. "
"source_classes must be a subset of target_classes."
)
corresponding_index = target_classes.index(class_name)
index_mapping[i] = corresponding_index
return index_mapping
def map_detections_class_id(
source_to_target_mapping: Dict[int, int], detections: Detections
) -> Detections:
if detections.class_id is None:
raise ValueError("Detections must have class_id attribute.")
if set(np.unique(detections.class_id)) - set(source_to_target_mapping.keys()):
raise ValueError(
"Detections class_id must be a subset of source_to_target_mapping keys."
)
detections_copy = copy.deepcopy(detections)
if len(detections) > 0:
detections_copy.class_id = np.vectorize(source_to_target_mapping.get)(
detections_copy.class_id
)
return detections_copy
def save_dataset_images(
dataset: "DetectionDataset", images_directory_path: str
) -> None:
Path(images_directory_path).mkdir(parents=True, exist_ok=True)
for image_path in dataset.image_paths:
final_path = os.path.join(images_directory_path, Path(image_path).name)
if image_path in dataset._images_in_memory:
image = dataset._images_in_memory[image_path]
cv2.imwrite(final_path, image)
else:
shutil.copyfile(image_path, final_path)
def train_test_split(
data: List[T],
train_ratio: float = 0.8,
random_state: Optional[int] = None,
shuffle: bool = True,
) -> Tuple[List[T], List[T]]:
"""
Splits the data into two parts using the provided train_ratio.
Args:
data (List[T]): The data to split.
train_ratio (float): The ratio of the training set to the entire dataset.
random_state (Optional[int]): The seed for the random number generator.
shuffle (bool): Whether to shuffle the data before splitting.
Returns:
Tuple[List[T], List[T]]: The split data.
"""
if random_state is not None:
random.seed(random_state)
if shuffle:
random.shuffle(data)
split_index = int(len(data) * train_ratio)
return data[:split_index], data[split_index:]
def rle_to_mask(
rle: Union[npt.NDArray[np.int_], List[int]], resolution_wh: Tuple[int, int]
) -> npt.NDArray[np.bool_]:
"""
Converts run-length encoding (RLE) to a binary mask.
Args:
rle (Union[npt.NDArray[np.int_], List[int]]): The 1D RLE array, the format
used in the COCO dataset (column-wise encoding, values of an array with
even indices represent the number of pixels assigned as background,
values of an array with odd indices represent the number of pixels
assigned as foreground object).
resolution_wh (Tuple[int, int]): The width (w) and height (h)
of the desired binary mask.
Returns:
The generated 2D Boolean mask of shape `(h, w)`, where the foreground object is
marked with `True`'s and the rest is filled with `False`'s.
Raises:
AssertionError: If the sum of pixels encoded in RLE differs from the
number of pixels in the expected mask (computed based on resolution_wh).
Examples:
```python
import supervision as sv
sv.rle_to_mask([5, 2, 2, 2, 5], (4, 4))
# array([
# [False, False, False, False],
# [False, True, True, False],
# [False, True, True, False],
# [False, False, False, False],
# ])
```
"""
if isinstance(rle, list):
rle = np.array(rle, dtype=int)
width, height = resolution_wh
assert width * height == np.sum(rle), (
"the sum of the number of pixels in the RLE must be the same "
"as the number of pixels in the expected mask"
)
zero_one_values = np.zeros(shape=(rle.size, 1), dtype=np.uint8)
zero_one_values[1::2] = 1
decoded_rle = np.repeat(zero_one_values, rle, axis=0)
decoded_rle = np.append(
decoded_rle, np.zeros(width * height - len(decoded_rle), dtype=np.uint8)
)
return decoded_rle.reshape((height, width), order="F")
def mask_to_rle(mask: npt.NDArray[np.bool_]) -> List[int]:
"""
Converts a binary mask into a run-length encoding (RLE).
Args:
mask (npt.NDArray[np.bool_]): 2D binary mask where `True` indicates foreground
object and `False` indicates background.
Returns:
The run-length encoded mask. Values of a list with even indices
represent the number of pixels assigned as background (`False`), values
of a list with odd indices represent the number of pixels assigned
as foreground object (`True`).
Raises:
AssertionError: If input mask is not 2D or is empty.
Examples:
```python
import numpy as np
import supervision as sv
mask = np.array([
[True, True, True, True],
[True, True, True, True],
[True, True, True, True],
[True, True, True, True],
])
sv.mask_to_rle(mask)
# [0, 16]
mask = np.array([
[False, False, False, False],
[False, True, True, False],
[False, True, True, False],
[False, False, False, False],
])
sv.mask_to_rle(mask)
# [5, 2, 2, 2, 5]
```
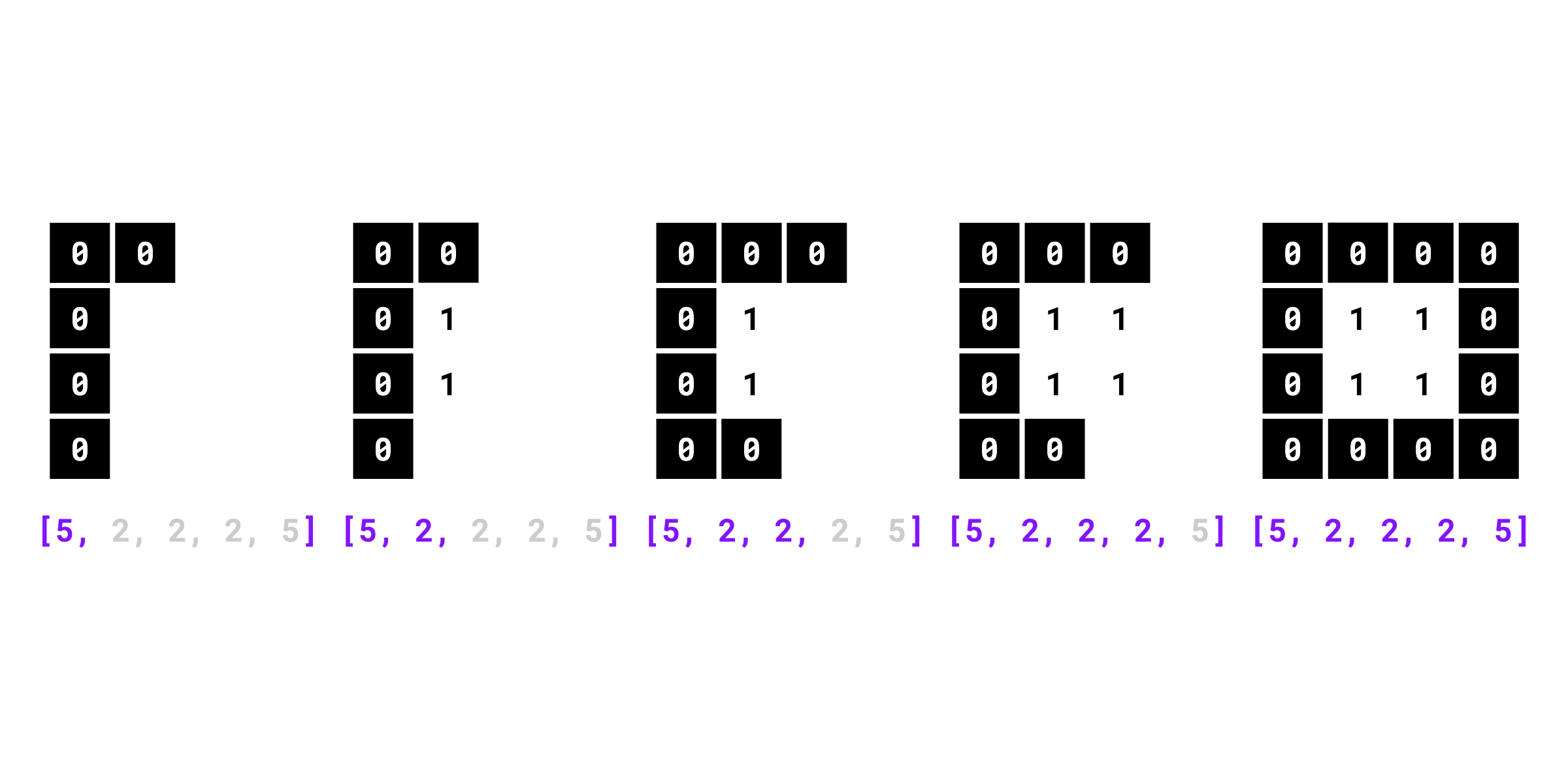{ align=center width="800" }
""" # noqa E501 // docs
assert mask.ndim == 2, "Input mask must be 2D"
assert mask.size != 0, "Input mask cannot be empty"
on_value_change_indices = np.where(
mask.ravel(order="F") != np.roll(mask.ravel(order="F"), 1)
)[0]
on_value_change_indices = np.append(on_value_change_indices, mask.size)
# need to add 0 at the beginning when the same value is in the first and
# last element of the flattened mask
if on_value_change_indices[0] != 0:
on_value_change_indices = np.insert(on_value_change_indices, 0, 0)
rle = np.diff(on_value_change_indices)
if mask[0][0] == 1:
rle = np.insert(rle, 0, 0)
return list(rle)